
Predicting Multiple Time Series with USA COVID-19 data using Machine Learning models
AUTHOR
John Ray Martinez (jbm332@drexel.edu)
This research is implemented in fulfillment of the requirements for the Applied Machine Learning Course of Master of Science in Data Science under Drexel University College of Computing & Informatics
Introduction
As novel coronavirus COVID-19 cases surge across the US, improving methods for prediction of COVID-19 cases in this country is extremely important. It is imperative that the hotspot is studied more thoroughly to slow down the outbreak while trying to find a cure and vaccine. Forecasting the time of future surge would minimize the impact of COVID-19 by taking timely preventive steps including public health early response such as lockdown, schools closures, and travel restrictions.
Therefore, accurate COVID-19 transmission rate forecasting is essential to better understand the current situation and plan for the future. This is also for public health authorities to implement interventions effectively in controlling the outbreaks. This would greatly minimize the social and economic impact of the disease.
Furthermore, the objective of this study is to determine whether it is possible to use one Machine Learning model on multiple time series data (COVID-19 new daily confirmed cases for each state) to project future COVID-19 confirmed cases.
DATA DESCRIPTION
The dataset was obtained from 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE. In addition, data from US States population data of 2019 (NST-EST2019-alldata) was obtained from United States Census Bureau.
The time series data is split into training set (01/22/2020 - 06/30/2020), validation set (07/01/2020 - 07/31/2020), and test set (08/01/2020 - 08/22/2020).
METHODOLOGY
Preprocessing includes feature engineering, data merging, feature selection, log and polynomial transformation, and categorical encoding. The performance of the following machine learning models is compared.
- Linear Regressor
- RandomForest Regressor
- Gradient Boost Regressor
- XGBoost Regressor
The general workflow for comparing the performance of machine learning models as shown in Figure 1 involves the following steps.
- Preprocessing of data
- Recursive forecasting using rolling window with 1-day ahead
- Use of each model and evaluation using R-squared, Root Mean Square Error and Mean Absolute Error
- Comparison of models via R-squared, RMSE and MAE, plotting test results of all models, and plotting of residual results of all models
 Figure 1. Workflow for measuring the performance of Machine Learning models.
Figure 1. Workflow for measuring the performance of Machine Learning models.
RESULTS
The metric evaluations show that XGBoost had the best results in terms of predicting the test dataset. On the other hand, Gradient Boosting outperformed all the models in training dataset. Furthermore, XGBoost has the best results among the models while showing its capability to do parallel processing as it clocked the fastest elapsed time.
 Table 1. Statistics for prediction of COVID-19 daily confirmed cases.
Table 1. Statistics for prediction of COVID-19 daily confirmed cases.
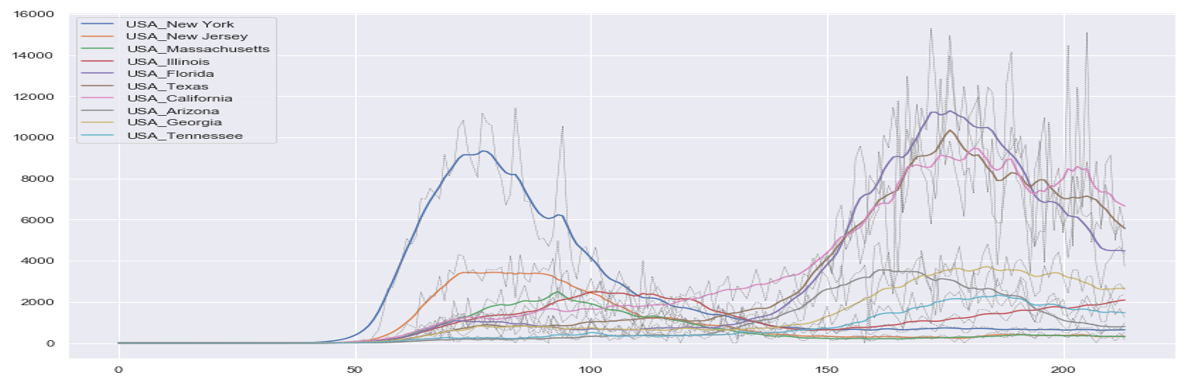
Plotting of test and residual results of all models in states which attributed the highest number of confirmed cases are shown below.
A. Texas
 Figure 2. Texas prediction plot over the test set.
Figure 2. Texas prediction plot over the test set.
 Figure 3. Texas residual plot over the test set.
Figure 3. Texas residual plot over the test set.
B. Florida
 Figure 4. Florida prediction plot over the test set.
Figure 4. Florida prediction plot over the test set.
 Figure 5. Florida residual plot over the test set.
Figure 5. Florida residual plot over the test set.
C. California
 Figure 6. California prediction plot over the test set.
Figure 6. California prediction plot over the test set.
 Figure 7. California rsidual plot over the test set.
Figure 7. California rsidual plot over the test set.
With the recent trend and issue of the coronavirus, the researcher hopes that this project will be relevant and helpful to other researchers, specialists, and especially public health surveillance systems. These people would benefit by knowing when to focus on this sickness and when the surge or resurgence would happen. Furthermore, it would help the public health authorities and governments alike in decision making whether to ease the lockdown or issue another lockdown for each state.
LIMITATIONS
First, the method does not include different control measures for each state such as level of social distancing and how these will change in the future. In addition, the available period of time is about half a year while considering around 50 US states which will result to approximately 11,000 data points; a relatively small data set. Moreover, despite focusing on US, the study does not include mapping of the virus’ trend to specific areas or regions in the country.
INSIGHTS AND CONCLUSION
The estimated values of COVID-19 daily confirmed cases were in good agreement with their related observed values and the used Machine Learning models, especially the ensemble method – Boosting models, could be used to forecast daily confirmed cases. These results are very worthwhile for the decision-making bodies or public health experts given that the decision is urgent.
For future work, merging more domain-related data like temperature, lockdown periods, etc, that have significant impacts in variation of number of COVID19 cases can be considered. In addition, the direct forecasting approach discussed by Souhaib Ben Taieb in his dissertation paper can be explored.